Beyond Supervised Learning:
Accelerating Business Insights with Reinforcement Learning
Author: Evie Fowler
Data science – the art of using data to draw insight and inferences around the way the world works – is a crucial component of business today. The modern business world is dynamic and fast-paced, though, and organizations that spend too much time on research and experimentation can quickly be left behind. In fact, the most common constraints on data science projects today are not computing power or skill but the availability of data and the time it takes to collect and analyze it. Luckily, predictive methods are evolving quickly and selecting the best one can radically improve the efficacy and time to implementation of a data science initiative.
To illustrate this concept, imagine an online retailer with a variety of products to sell. The retailer would like to increase sales by advertising to their customers. Since ads are expensive, they’d like to do this in the most efficient way possible. That means offering customers promotions tailored to their own interests, rather than ads for a random selection of products. Since few customers offer this kind of information unsolicited, the challenge is to quickly and efficiently learn each customer’s preferences through predictive analytics.
Test and Learn
Supervised Learning
The traditional supervised learning approach to this problem would involve serving each customer a variety of ads over time, tracking their performance, and then only serving ads of the most popular type going forward. This works well enough, and certainly beats out the naive approach of serving a random mix of ads indefinitely.
A Slow Start
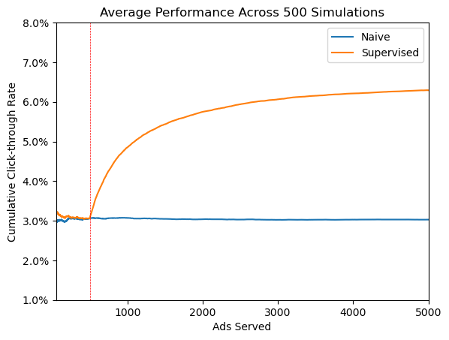
This approach has some drawbacks though. For one, there’s the burn-in period required to learn each customer’s ad preferences – the time spent serving random ads and observing their performance without drawing any inference. Since click-through rates are generally fairly low (even a great ad served to interested customers might only get 3-4% click-through), it can take several hundred rounds of ads to develop a confident estimate of the performance of each promotion category.
No Guarantees
This process is also not without error. Even with 500 rounds of ads devoted to establishing customer preference, it’s still possible to reach the wrong conclusion about a customer’s ad preferences. The figure below shows the cumulative click-through rate after 5,000 ads are selected via supervised learning. When the process is successful, each line converges toward the probability of an individual customer clicking on a well-targeted promotion – 6-7%. But note how many of the simulations converge to a much lower click-through rate than that. This is because when event rates are low, it’s possible for random chance to obscure true patterns, even in a robust sized sample.
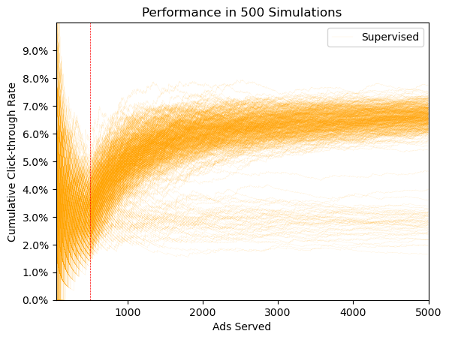
Error isn’t the only issue, though. Those initial burn-in rounds are dedicated exclusively to exploration of the customer’s preferences. The algorithm does not even begin to exploit the learnings from the exploration phase until a clear picture of those preferences emerges, and after that it does not explore at all. Exploration (collecting information) and exploitation (acting on the information already collected) are competing goals in supervised learning, with each carrying an opportunity cost. Too firm a commitment of time and resources to exploration limits the potential to fully exploit the lessons learned through analytics. On the other hand, pivoting too early or too permanently to the exploitation of past research can mean missing changes to evolving customer trends, or uncritically committing to inferences that weren’t correct.
Test and Learn…Faster
One way to improve on this balance between exploration and exploitation is with reinforcement learning. Broadly speaking, reinforcement learning aims to optimize the cumulative outcome of a series of actions, even when this differs from optimizing the outcome of the very next action taken. For our retailer, this means optimizing cumulative click-through rate, rather than seeking to maximize the response to each individual ad selection. Reinforcement learning works best when there are a finite number of actions that could be taken at any given time (for example, a finite number of ad categories that could be served) and a finite number potential responses to them (for example, the coveted click-through on an ad, or a scroll-past).
Reinforcement Learning
A problem is a good candidate for inference through reinforcement learning when it can be framed up like this:
- Estimate the value of each available action (e.g. the expected result of serving an ad of each type).
- Use a reinforcement learning algorithm to choose an action (e.g. choose which type of ad to serve next).
- Review the outcome of the selected action and use it to update the estimated value of each action (e.g. observe whether the ad was clicked and use that to infer what ads are preferred).
- Repeat steps (2) and (3) as needed.
Step (2) is the crucial one. There are a number of reinforcement learning algorithms available to guide this selection process. One popular option is the epsilon-greedy algorithm. This algorithm dynamically toggles between the exploration and exploitation phases according to a parameter denoted by epsilon. It functions like this:
- Use the epsilon-greedy algorithm to choose an action.
- Most of the time, greedily exploit previous learnings by choosing the most valuable action.
- A small fraction of the time, specified by epsilon, explore by choosing another action at random instead.
The value of epsilon can be adjusted to prioritize exploration when uncertainty is high or to prioritize exploitation when need is urgent. The parameter can even be adjusted during implementation, dropping down to maximize exploitation as observations roll in and confidence in inference grows.
In Practice
For our hypothetical retailer trying to measure and appeal to each customer’s ad preferences, the whole process now looks like this:
- Estimate the value of each potential ad using prior knowledge of the customer and ad space.
- Use the epsilon-greedy algorithm to choose which type of ad to serve next.
- Most of the time ([1 – epsilon]%), exploit existing knowledge by serving an ad in the category with the highest historical click-through rate for this customer.
- The rest of the time (epsilon%), explore unknown territory by serving an ad in a random category.
- Decrease epsilon after each 100 ads are observed.
- Observe the cumulative click-through rate for each type of advertisement and use it to update the estimated value of each available action.
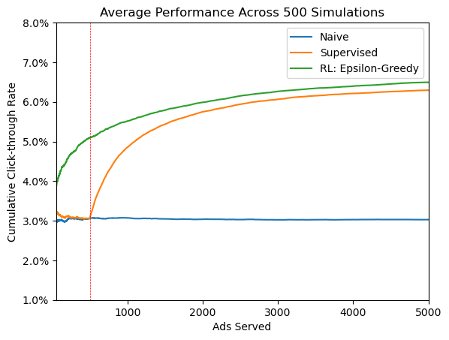
The figure below shows how each ad selection algorithm impacts click-through rate for our retailer across 500 simulations.
Promising Beginnings
For our retailer, ad selection via reinforcement learning outperforms traditional supervised learning by nearly double across the first 500 ad opportunities. Note that there is no burn-in period required for this method: the reinforcement learning algorithm starts acting on customer preferences immediately. This makes it a great solution for the many data science applications where good, labeled data is limited, or where quick decision making is crucial.
No Sunk Costs
The reinforcement learning algorithm outperforms traditional supervised learning in the long run as well. This is because the reinforcement learning algorithm never stops learning about its subjects. Recall that when click-through rates are low patterns can be obscured even with robust sample sizes. Supervised learning is prone to error in these situations because it calls for an assessment to be made as soon as practical and never revisited. Reinforcement learning, on the other hand, calls for continual collection and evaluation of information, and a change of approach as needed. This makes reinforcement learning a great choice for the types of dynamic, constantly evolving environments where many businesses operate.
Learn More
For more information about reinforcement learning or other data science-related topics, make sure to follow our blog or sign up for our mailing list. If you would like to utilize our dedicated team of specialists, contact us today.