Author: Ani Madurkar
Industry Data Science has diverged into a few dominant verticals as the field has matured, but the primary specialty has been Enterprise Machine Learning (with Product-centric Data Science as a close second). The realm of Enterprise Machine Learning, so far, has looked quite similar to how Kaggle looks — hacky ML notebooks that get the job done for a short duration of time on a specific task (sometimes with a small team, but the scope of impact is relatively minor).
In recent years, Data/AI roles and projects have gotten large budgets to bring about the promised holy grail of value each organization is looking for. Unfortunately, the industry is still lacking in fully realizing the value of most of its investments in AI, considering how few notebooks actually end up in production (and work). The field has recently delved headfirst into the world of MLOps to deal with this massive impediment.
MLOps, or Machine Learning Operations, is a set of tools, practices, techniques, and cultures that ensure reliable and scalable deployment of machine learning systems. Most Enterprise ML projects rarely make it past Level 0, limiting the business’s ability to realize true value and keeping ML projects in sandbox mode in perpetuity. This post will clarify the differences between Level 0 and Level 1 and suggest how we can get to a more advanced stage of MLOps maturity.
MLOps Level 0
MLOps levels are differentiated by the amount of automation in the system, and manual processes dominate Level 0. It is manual, script or notebook-driven, and sometimes interactive. This is a common stage for many ML teams, as this is how proof of concept work is done: they iterate quickly in notebooks, refactor code into a script, and rarely see significant improvements past this point.
Why is this level not sufficient?
It strongly depends on your use case and application, but most use cases need more than just a Jupyter notebook that less than five people can use. The lack of value realization of machine learning projects reflects the vast gap we have in creating automated systems beyond manually run notebooks and scripts.
As we increase the maturity of our system to Level 1, we increase the velocity of training and deployment of new models, which is incredibly crucial when it comes to ML. Most models are only determined to be “useful” when used on real data, and they all require monitoring and updating as the real world (and data) evolves. So, increasing our velocity to train and deploy new models is imperative to the health of our system.
The best version of Level 0 looks like this:
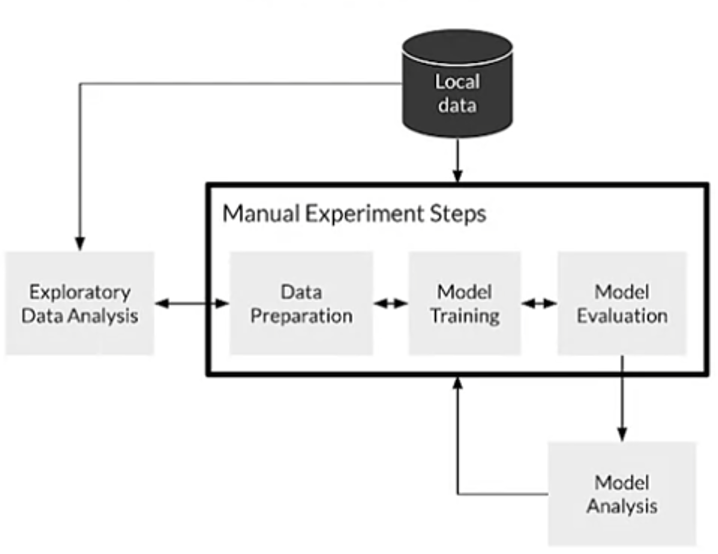
This diagram should look familiar as it is the primary modeling workflow today. Local data feeds into a notebook to run exploratory data analysis (EDA) and into a set of scripts that perform data preparation, model training, model analysis, and model evaluation through loose chaining and manual execution. This workflow doesn’t live in production, but the results are usually evaluated by the data science team and then pushed into a database table or presented in a PowerPoint and forgotten about.
The issue with this is it creates silos for the Data Science teams and separates them from the business.
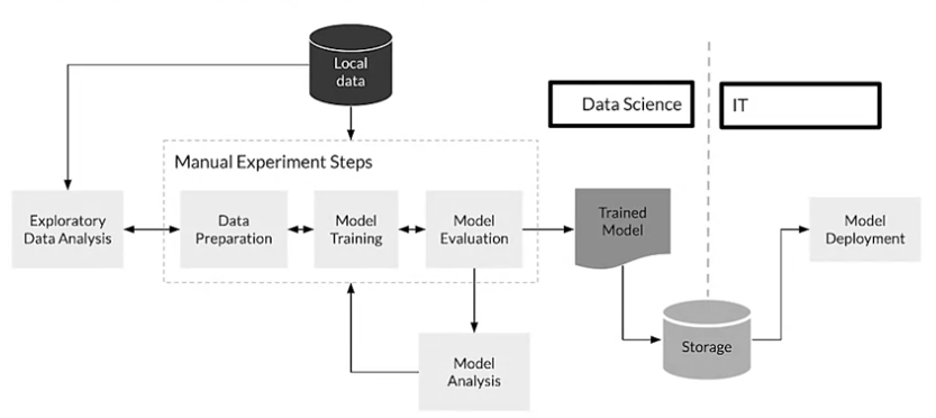
This disconnect between Data Science and Operations teams can open the door to a myriad of issues, like training-serving skew. Training-serving skew is a common and damaging issue in machine learning. It is the difference between performance during training and performance during serving which can be caused by:
- A discrepancy between how you handle data in the training and serving pipelines.
- A change in the data between when you train and when you serve.
- A feedback loop between your model and your algorithm.
This model also allows for far less frequent releases as there is no continuous integration/deployment incorporated (and unit testing is usually ignored).
This approach deploys the model as a prediction service rather than deploying the entire ML system. Level 0 can be sufficient if a new model is only expected to be deployed a couple of times a year. In reality, data changes happen quite frequently, requiring a more frequent deployment than level 0 offers. With this workflow, it can be common to always be in a position of firefighting or “playing catch up” with your model as it is evolving at a snail’s pace in comparison to the real world.
Some key challenges with Level 0:
- Lack of active monitoring of model quality in production
- Retraining production models with new data
- Continuous experimentation and integration of improved data and model versions
Essentially, what MLOps Level 0 is lacking is a nervous system that can effectively connect disparate systems with a series of checks and balances that monitor and maintain the system’s overall health.
MLOps Level 1
The first point of optimization that Level 1 brings is rapid experimentation and repeatable training of models. This can be introduced by creating orchestrated experiments for your training workflow, which automates the transitions immediately.
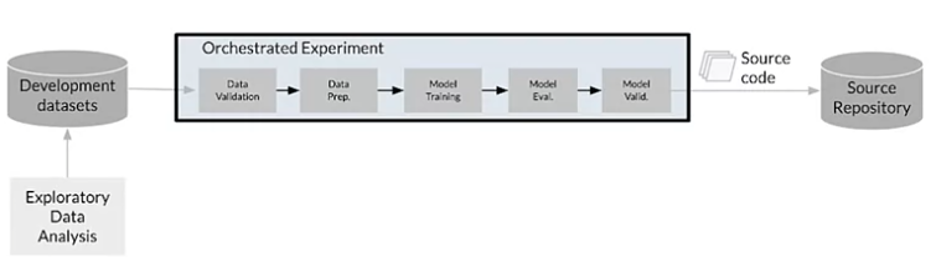
You want each component in an ML system to be composable, reusable, and shareable across team members and across the pipeline. The way to accomplish this is by containerizing different components and modularizing code (even what lives in Jupyter) to ensure the training and testing environments are as similar as possible.
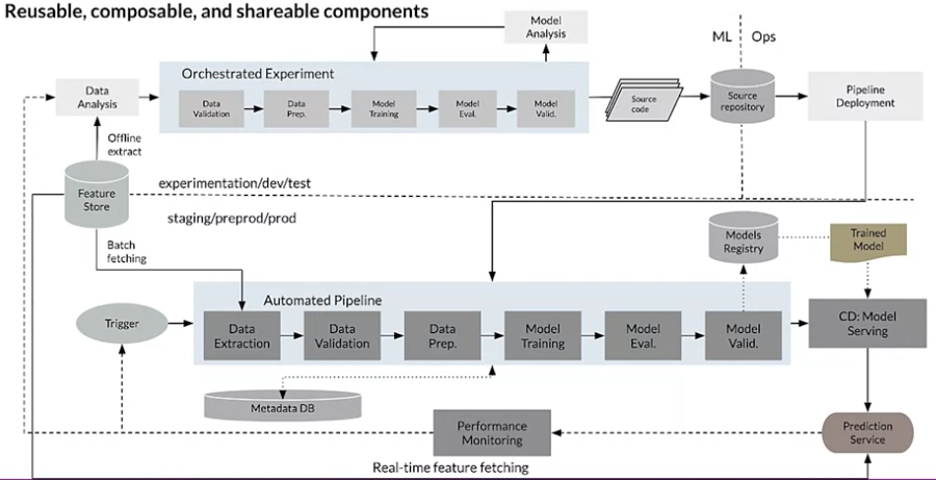
The big difference in Level 1, as opposed to Level 0, is that you are deploying an entire machine learning pipeline to production instead of just an ML model. Creating composable components in each stage reduces the dependencies and risks of learning from live, new data.
The pipeline in production is kicked off by one or more triggers that execute when new data is seen that performance monitoring shows is drastically different from what the model was trained on initially. Data and Concept Drift detection are some key triggers that you can use to execute the automated pipeline in production. These two drifts are some of the most common ways machine learning systems can fail over time. Data drift is where the model’s input distribution (the distribution of features) changes. Concept drift is where the functional relationship between the model’s inputs and outputs changes.
Data Extraction and Data Validation are necessary steps in the production pipeline because you may have features that have changed over time, new features that didn’t exist previously, or some other unforeseen change. It’s imperative to validate the schema and extract the right data that is needed. Data Validation can do anomaly detection to check for discrepancies between training and serving data to ensure the later downstream steps of the pipeline comply. Data Extraction hits a Feature Store that keeps a repository of preprocessed and vetted features to ensure minimal variance amongst different teams and projects trying to use the same features (with or without preprocessing). The Feature Store can be an excellent solution for quickly retrieving summary statistics as well.
A Model Validation step at the end ensures that the new model performs better than the current before registering it in the Models Registry and serving it to replace the old one. Model Validation can include model performance on training/testing data, but it can also include fairness and bias checks to ensure it performs equitably across various slices and segments of the population.
Each pipeline execution is recorded to help with data provenance and logging. The Metadata DB tracks information like pipeline runtime, input and output artifacts, details for each step, and more. This is helpful as tracking intermediate outputs helps you resume from where you left off in case the pipeline stops due to some error.
The whole goal of this Level is greater automation to increase the velocity of training and deployment of new (and better) modeling pipelines. This approach provides Data Science teams far greater control over the entire workflow and integration with the Operations team to handle deployments at an immensely faster pace.
Going Beyond Level 1
The goal of MLOps maturity is to automate the training and deployment of ML Models into the core software system and provide monitoring. This is done to increase the velocity of training and deployment so value can be realized from large-scale machine learning projects.
Level 2 automation consists of a constant cycle of logs, triggers, monitoring, and more integrated directly into the software stack of the organization. This is still quite aspirational for most, so I didn’t cover it in much depth here. Level 2 will likely change by the time the industry is fully ready to get there, especially with Cloud infrastructure.
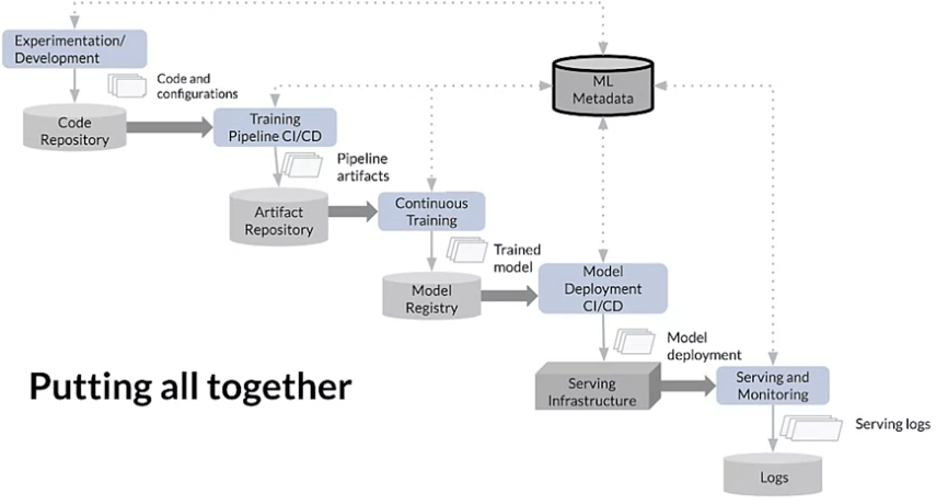
In any case, it’s imperative that we start thinking past our manual, un-tested Jupyter notebooks that work on our local machines. We need to think at scales much larger to realize value from our models in the real world. MLOps is how we get there.
Fulcrum Analytics is a specialized Data Science and Machine Learning consulting firm in New York that helps clients build end-to-end Data Science solutions for their high-value business needs. Contact us today if you have any questions on how we can help you.
References:
[1] Treveil, et. al., O’Reilly Media, Introducing MLOps
[2] DeepLearning.ai, Coursera, Machine Learning Engineering for Production (MLOps) Specialization
[3] Chip Huyen, Stanford,po CS 329S: Machine Learning Systems Design
[4] Awesome MLOps