Author: Igor Pshenychny
Jupyter Notebook has become the de facto standard for data analysis. An acronym of the three main coding languages it supports: Julia, Python, and R, Jupyter Notebook provides a user-friendly integrated development environment (IDE) and has been evolving over time to become a go-to tool for data scientists. Jupyter Notebook facilitates a wide range of data science tasks such as Mathematical Modeling, Exploratory Data Analysis, Machine Learning, and Data Visualizations. Below, we take a look at a couple enhancements developed specifically for Jupyter Notebook: extensions and a thematic package.
Table of Contents
For anyone coding within a development environment, the proper use of a table of contents is to orient and maintain perspective on the structure of the analysis being worked on. It not only acts as a navigational guide for future users but also as a transportation system allowing you to jump to any section of the notebook, all of which are on display in either a sidebar or floating window. Although quite similar to Google’s Colab table of contents sidebar, the Jupyter Notebook Table of Contents extension sets itself apart by being draggable, resizable, collapsable, and dockable. A delightful additional feature includes a TOC cell at the top of the notebook that translates into navigational links when saving the notebook as an HTML file.

Codefolding & Collapsible Headings
The Codefolding extension enables Jupyter to fold code within cells, with 3 modes which can be useful for class/function definitions, saturated for/while loops, and conditional statements. Additionally, you can indent through first line comments, essentially folding the entire cell if needed. This is useful in situations such as hiding cells that expose and describe results or perform temporary modifications to a dataset. Subsequent comments in the cell, however, do not fold. If the comment appears anywhere after the first line, it won’t be foldable.
There is also Magic folding. Magic commands are features added to Python to enhance the user’s experience by providing shortcuts to common commands such as executing a Python file, copying code from other modules, or listing all defined variables and are denoted with either % or %% (ex. % time). Similar to first line comments, if you place a magic command in the first line of a cell it can be folded, but subsequent magic commands will not.

The Collapsible Headings extension enables collapsing of entire multi-cell sections, providing the benefit of skipping through lengthy sections of the notebook to those that contain the results. The collapsed/expanded statuses of the headings are saved in the cell metadata, and reloaded when the notebook loads. This is particularly useful when you run an important section only once during an entire analysis i.e. a preprocessing data section. Once you’re done executing that collection of cells, a collapsable heading could save you the time it takes to scroll through that section every time you traverse the notebook (unless you have a quick way of jumping between titled sections, such as using the Table of Contents sidebar).
One caveat for both the Codefolding and Collapsible Headings extensions is that exporting a notebook will undo any folds unless you apply a custom preprocessor for nbconvert. The preprocessor is installed when you install the jupyter_contrib_nbextensions package and the steps to execute are located on the nbextension Codefolding documentation page.
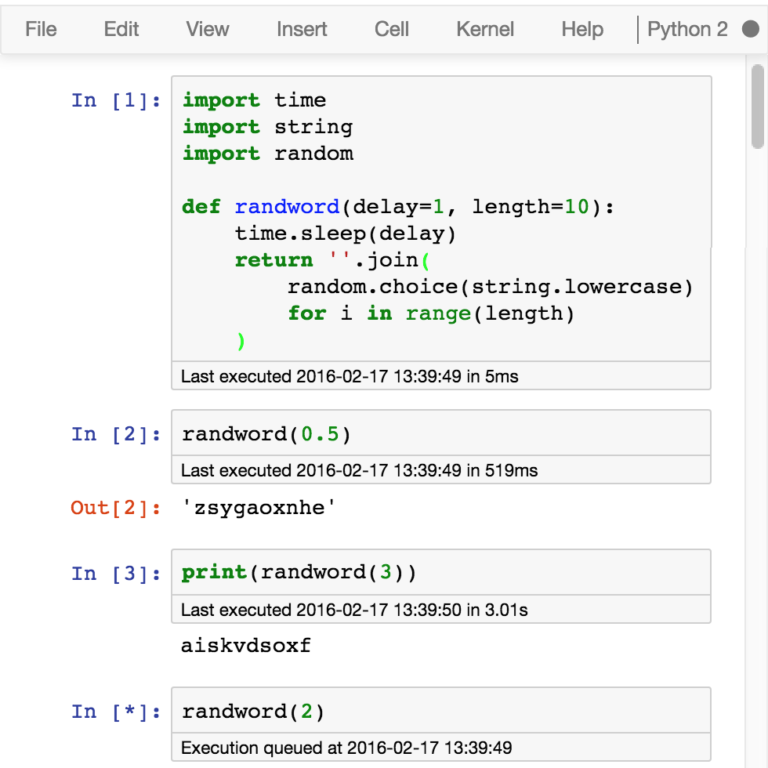
ExecuteTime
Execution Time is another useful extension for Jupyter Notebook. When enabled, it displays the time that each cell executed and how long it took right below the cell. Whether you are testing a connection with a database, loading in data to your notebook, or just processing data, it allows you to gauge how long each cell operation takes to complete.
Most of the time one wouldn’t care whether they can shave 150 milliseconds off their execution time, but those few milliseconds really add up when dealing with big data. Quickly testing to see the difference between a lambda function versus a standard for loop on a very small section of your data (ex. One millionth of your total data set) would reveal the more efficient path. The code that’s 150 milliseconds faster could make the difference of 5 hours between run times when scaling up. This sanity check method also applies to Machine Learning where one might try to fit a smaller version of a training dataset before training a larger one.
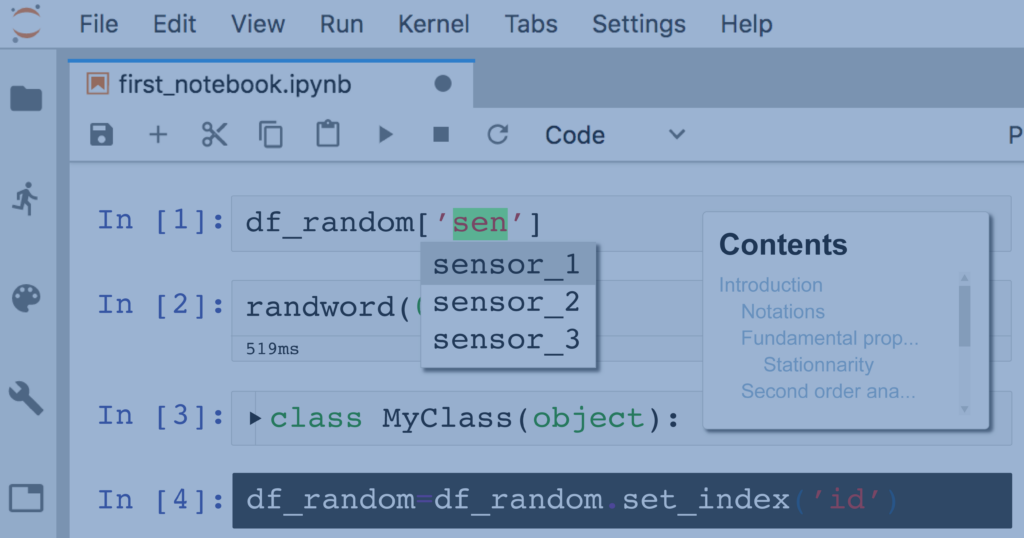
Hinterland
Hinterland is a Jupyter Notebook extension that allows tab-activated autocomplete whenever one types out a variable name. Autocomplete is a useful quirk in other IDEs but lacking in Jupyter out of the box. Having variables, dataframe columns, functions, methods, and the likes of which load after typing out the first 3 characters is Python’s way of finishing your sentences for you. Similar labels such as “date_col1” and “date_col2” are less likely to be mixed together since Hinterland will autocomplete up until the first location the labels split. Hence Hinterland will autocomplete to “date_col” while providing a dropdown menu providing options of date_col1, date_col2, and all other similar date_col labels.

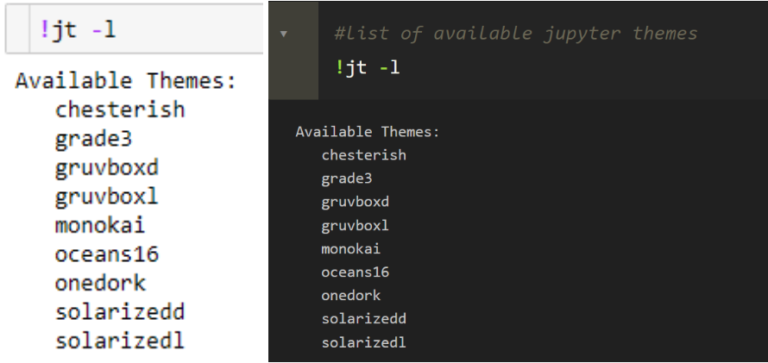
Themes
Imagine your preferred text editor. If you’ve named one of the heavy hitters such as Visual Studio, Sublime, or even Notepad++ then there’s a good chance you’re a fan of the dark theme. The default theme of Jupyter Notebook is light, but with the Jupyter Themes extension you can change themes to one that better aligns with your visual preferences.
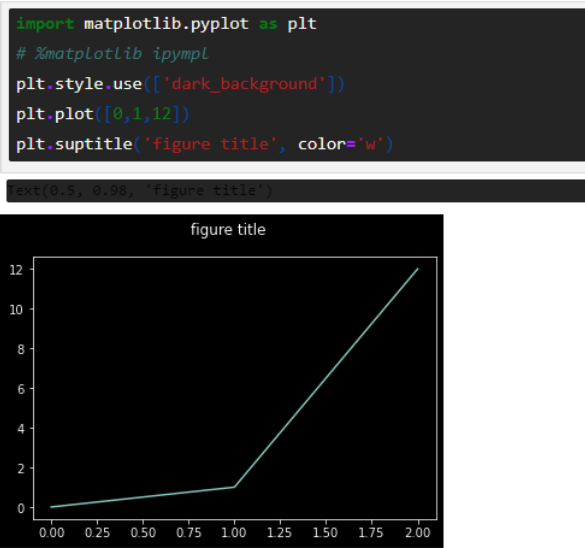
Jupyter Themes does have a couple of drawbacks: matplotlib charts axis would become unreadable and you’ll have to experiment with setting a different background color. An additional drawback is if you’d like to save your code as an html file, then the entire html page will be black but every cell and markdown block will be colored to the theme you’ve had before. So it’s recommended to reset any style changes if you’re going to export your work.
Conclusion
Enriched documentation, project management, and interactive development are what Jupyter Notebook already provides. Extensions discussed here additionally aid the influence Jupyter has on creative exploration and provide a higher standard for an IDE. When it comes to developing code efficiently, productively, or even personally, these extensions can help customize your work. They make this already great tool for analysis even better. If you use Jupyter Notebook often, let us know how these simple pleasures changed your experience.
Fulcrum Analytics has provided data science consulting services across industries for over 25 years to produce both quick wins and long lasting impact for our clients. For more data science tips, tricks, and information on the latest trends in the industry, make sure to check out the rest of our blog posts. If you’re looking to learn more about how Fulcrum can quickly increase or augment your organization’s data science capabilities, contact us today.


